Sample Subset Optimization (SSO)
Application to imbalanced data sampling
Summary
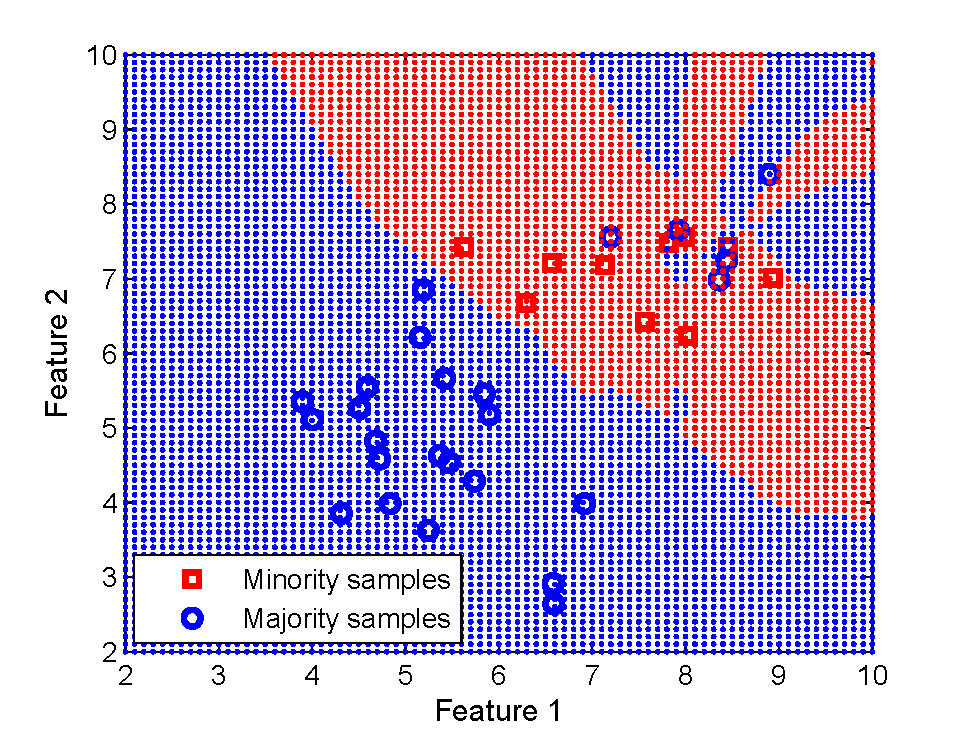
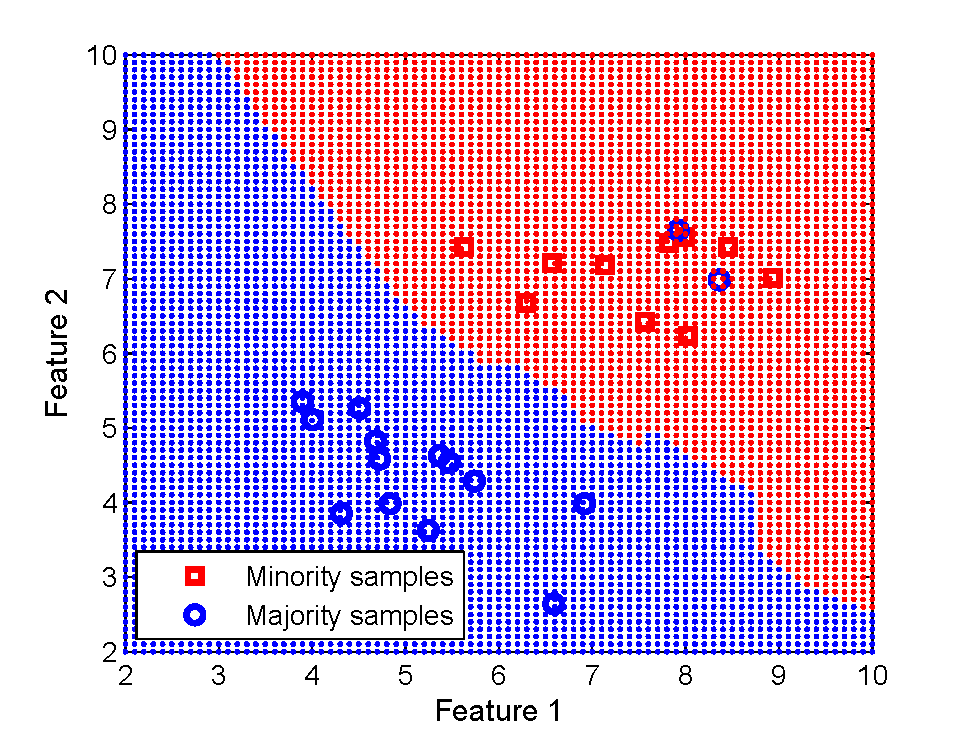
Sample subset optimization (SSO) [1] can be used as an intelligent method for sampling from imbalanced data [2]. It works by ranking and selecting most informative samples from the majority class to form a balanced dataset with samples from minority class.
GUI version
The GUI version SSOgui.jar will run by a double-click assuming you have Java installed in your computer. The dataset exampleData.txt could be used to test the program. When using your own dataset, please follow the way each column and row is defined as in the exampleData.txt. For the example dataset, the instances from 31 to 35 are noise introduced to the majority class but generated by minority class distribution. Therefore, the goal is to give them a fairly low rank when sampling is applied to select from the majority class. SSOgui.jar is straightforward to use and self-explanatory. Let me know if you need further detail on how to use it.
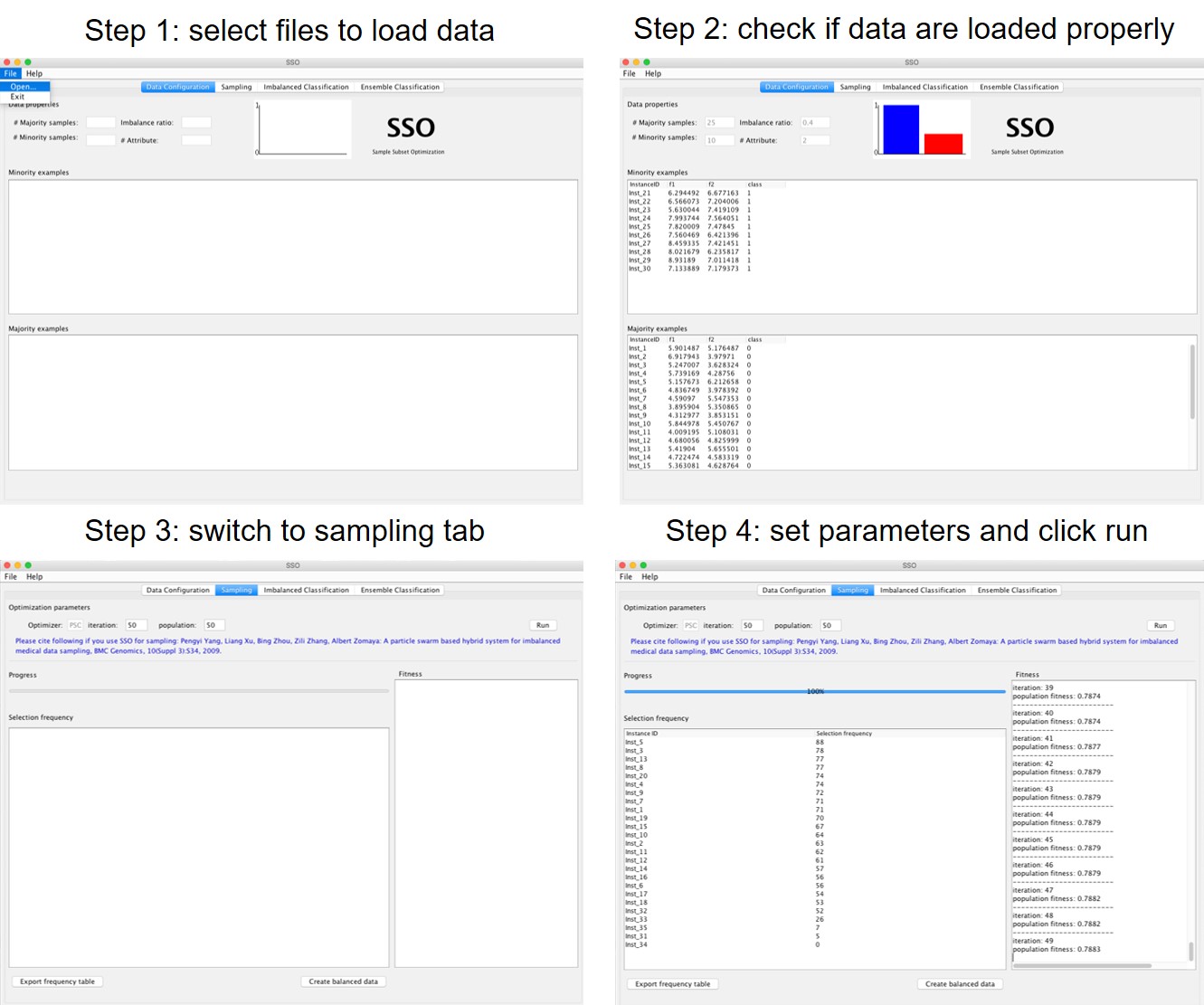
Please follow the following four steps to use the SSOgui.jar
SSOgui source code is available from here
Command line version
To try out the command line version, please going through the following steps:
- Download and unzip SSOSampling_v.1.1.zip
- Download exampleData.txt. Note that example data is a
tab-delimited file and the command line version expect the data in ARFF format. So you will need to run
the TAB2ARFF.pl converter first to convert data format. This requires PERl to be installed in your computer.
perl TAB2ARFF.pl exampleData.txt > exampleData.arff
- To obtain the general information about the program, issue following command in command line without parameters:
java -jar SSOSampling.jar
- To run SSOSampling on example dataset:
java -jar SSOSampling.jar -f example.arff
SSOSampling source code is available from here